CSV-Import
Mit dem CSV-Importer können mehrere Datensätze, die in einer tabellarischen Struktur vorliegen, auf einmal hochgeladen werden. Diese Methode eignet sich besonders gut, um weniger umfangreiche Datensätze (etwa Listeneinträge oder Rumpfdaten eines Objekt-Datensatzes) in CODA einzuspielen. Der CSV-Importer stößt jedoch an seine Grenzen bei komplexen und verschachtelten Datensätzen (hierfür eignet sich der JSON-Importer besser, für individuelle Beratung steht das CODA-Team gerne zur Verfügung). Zur Durchführung eines Imports mit dem CSV-Importer müssen bestehende Datenquellen zunächst in das CSV-Format umgewandelt werden.
Vorbereitung
CSV-Datei generieren
Im CSV-Format (“Comma Separated Values”) sind Datensätze jeweils in Zeilen gespeichert. Die einzelnen Informationen aus den Datensätzen sind dann mit einem Trennzeichen (meist Kommata oder Semikola) voneinander getrennt. Die erste Zeile einer CSV-Datei wird meist als Überschrift für die einzelnen “Spalten” verwendet.
Beispiel einer CSV-Rohdatei:
Name;Geburtsdatum;WikiData-Item
Grace Jones;04.04.1948;Q297538
Karl Willetts;21.09.1966;Q4843436
Wird ausgespielt zu:
| Name | Geburtsdatum | WikiData-Item |
|---|---|---|
| Grace Jones | 19.05.1948 | Q450429 |
| Karl Willetts | 21.09.1966 | Q4843436 |
CSV-Dateien können leicht aus Excel-Tabellen erstellt werden, auch OpenRefine ermöglicht einen Export der Projekte als CSV-Datei. Wichtig ist dabei, dass die Datei mit UTF-8 oder UTF-16 kodiert ist, andernfalls werden Sonderzeichen nicht richtig dargestellt.
Hinweis zu Excel
Der normale CSV-Export in Excel ist standardmäßig nicht UTF-8-kodiert! Klicke stattdessen in Excel im “Exportieren”-Menü auf “Speichern unter” und wähle anschließend als Dateityp “CSV UTF-8” aus.Damit deine CSV-Datei richtig ausgelesen wird, gilt es noch folgende Dinge zu beachten:
- Falls das Trennzeichen in einem Text in der CSV vorkommt, müssen Anführungszeichen (doppelt oder einfach) den Text umgeben. In Excel geschieht dies in der Regel automatisch, in OpenRefine sollte beim Export über die Schaltfläche “Custom tabular…” -> “Download” die Checkbox “Always quote text” angewählt werden.
- Das Format in jeder Spalte sollte immer gleich sein! Das gilt für Datumsangaben, Zahlen, Personennamen, etc.
- Zahlen sollten immer den gleichen Separator für Vor- und Nachkommastellen nutzen
CODA-spezifische Anforderungen
Mehrfachfelder
In einem Feld der CSV-Datei können mehrfache Einträge stehen, die in ein Mehrfachfeld in CODA gehören. Diese Einträge müssen aber durch Zeilenumbruch getrennt werden. Wenn also Objekt1 die zusätzlichen Bezeichnungen “Name_1” und “Name_2” hat, dann können diese in der CSV-Datei in einem Feld untergebracht werden, solange sie durch Zeilenumbruch getrennt sind.
- Wenn in einer Mehrfachgruppe verknüpfte Angaben stehen, zum Beispiel Personen mit ihrer jeweiligen Rolle, dann werden in Mehrfachfeldern die Felder in gleicher “Zeilenhöhe” miteinander gekoppelt:
| objekttitel | beteiligte_person[].name | beteiligte_person[].rolle |
|---|---|---|
| Diamond Life | Adu, Sade Millar, Robin |
Künstler*in Produzent*in |
| Die Wüstensöhne | Laurel, Stan Hardy, Oliver |
Doof Dick |
Verweise auf Normdaten mit Plug-Ins (GND, Getty, GeoNames)
Hier muss ein Link und eine Bezeichnung angegeben werden, und zwar in folgendem Format, das immer gleich ist, egal auf welche der Datenbanken man verweist. Dabei kann man Zeilenumbrüche und Leerzeichen auch weglassen, wichtig ist nur, dass das Folgende in einem einzelnen Feld deiner Tabelle bzw. CSV-Datei steht. (Es handelt sich hier um ein JSON-Objekt, das in einem Feld der CSV-Datei steht.)
{
"conceptURI": "https://d-nb.info/gnd/130579653",
"conceptName": "Morlock, Max"
}
Über das Import-Mapping wird dann festgelegt, um welche Referenz es sich tatsächlich handelt (GND/Getty/GeoNames), sodass die Information in CODA dem richtigen Feld zugeordnet wird.
Links (in Link-Feldern)
Verweise auf alle anderen Datenbanken verwenden das CODA-Mehrfachfeld Klassifikationen (siehe hier). Hierfür kriegen der Klassifikationstyp und die URL in deiner Tabelle bzw. CSV-Datei je eine eigene Spalte. Der Link wird wieder als JSON-Objekt dargestellt und kann optional auch eine Link-Beschreibung enthalten (siehe Beispiel). Als Spaltennamen kannst du zwecks automatischen Import-Mappings folgende wählen: classification[].type und classification[].link. Zum Beispiel:
| classification[].type | classification[].link |
|---|---|
| Wikidata | { “url”:“https://wikidata.org/wiki/Q666", “text_plain”: “Aussagekräftige Link-Beschreibung” } |
| IPNI | { “url”:“https://ipni.org/n/30004138-2" } |
Koordinaten
Koordinaten werden ebenfalls als JSON-Objekt aufbereitet. Die eigentlichen Koordinaten stehen in Dezimalschreibweise (ohne N/E-Angabe) bei “lat” bzw. “lng”. Zusätzlich empfiehlt sich die Angabe eines Icons (FontAwesome) sowie einer Farbe für das Icon, damit die Koordinaten in der CODA-Nutzeroberfläche auf Karten dargestellt werden können. Folgendes steht in einem einzelnen Feld der Tabelle bzw. CSV-Datei (Zeilenumbrüche und Leerzeichen kann man weglassen):
{
"mapPosition":{
"iconName":"fa-map-marker",
"iconColor":"#b8bfc4",
"position":{
"lat":8,
"lng":10
}
}
}
Dateien/Digitalisate
Es besteht die Möglichkeit, während des CSV-Imports bereits in CODA vorhandene Digitalisate mit den neuen Objekt-Datensätzen zu verknüpfen oder neue Digitalisate im gleichen Zug mit hochzuladen. Dies funktioniert ähnlich wie bei den Mehrfachfeldern auch mit mehreren Digitalisaten gleichzeitig.
Willst du bestehende Dateien verknüpfen, so kannst du in einer Spalte die Namen (Titel) der Digitalisate angeben und während des Import-Mappings diese Spalte dem Feld files[].file und dann dem Sub-Feld name#de-DE bzw. name#en-US (je nach Sprache, in dem die Datensätze zum Digitalisat vorliegen) zuordnen.
Um neue Digitalisate oder Dateien direkt während des CSV-Imports hochzuladen, müssen diese über einen Server bereitgestellt werden. Sollten die Daten auf der Festplatte deines PCs vorliegen, eignet sich die Nutzung eines lokalen Webservers, den du zum Beispiel mit der Software Servez erstellen kannst. Wähle in Servez das Verzeichnis aus, das deine Digitalisate enthält und achte darauf, dass die Checkbox bei “Set CORS headers” ausgewählt ist. Mit einem Klick auf “Start” kannst du den Server starten (er muss während des gesamten Importvorgangs live geschaltet sein). Anschließend bekommst du unten im Bereich “Log” eine URL angezeigt, unter der deine Dateien zu finden sind (du kannst dies auch mit dem Browser testen). Füge diese URL (inklusive des Ports, z.B. 8080) an den Dateinamen deiner Digitalisate an.
Beispiel (s. Spalte digitalisat):
| objekttitel | digitalisat |
|---|---|
| Aufnäher “Crypta” | patch_crypta.jpg |
| Stereoskopische Aufnahme eines Queen-Konzerts | bildkarte_0001_recto.tif bildkarte_0001_verso.tif |
Beispiel nach Korrektur der Dateinamen (s. Spalte digitalisat):
| objekttitel | digitalisat |
|---|---|
| Aufnäher “Crypta” | http://localhost:8080/patch_crypta.jpg |
| Stereoskopische Aufnahme eines Queen-Konzerts | http://localhost:8080/bildkarte_0001_recto.tif http://localhost:8080/bildkarte_0001_verso.tif |
Während des Imports werden die Digitalisate über den lokalen Server bereitgestellt und von dort in CODA hochgeladen.
Objektbiographie/Ereignisse
CSV-Import der Objektbiographie
Verschachtelte Ereignisse, die Mehrfachangaben beinhalten (bspw. mehrere Personen oder Orte) sind nur schwer per CSV zu importieren. Daher eignet sich der CSV-Import derzeit nur für flache Ereignisse, bei denen für jedes Feld maximal eine Information vorliegt. Für den Import komplexer Ereignisstrukturen eignet sich der JSON-Import deutlich besser.Relationen
Wenn ein Objekt eine Referenz auf ein anderes Objekt enthält, dann können nicht beide gleichzeitig per CSV importiert werden, weil man nur Referenzen zu Objekten erstellen kann, die bereits in CODA vorhanden sind. Daher muss man die Objekte, die einander referenzieren, in unterschiedliche Tabellen bzw. CSV-Dateien packen. Bei dem Objekt, das zuerst importiert werden soll, darf die Referenz nicht importiert werden. Das Objekt, das als zweites importiert wird, kann mit der Referenz zum ersten Objekt importiert werden. Das kannst du umsetzen, indem du das Feld für die Referenz nur beim Import-Mapping für das zweite Objekt auswählst. (Die wechselseitige Referenz wird dann beim Import automatisch erstellt.)
Import-Workflow
Den CSV-Importer findest du über einen Klick auf das Werkzeug-Symbol ( ) auf der linken Seite:
CSV-Importer
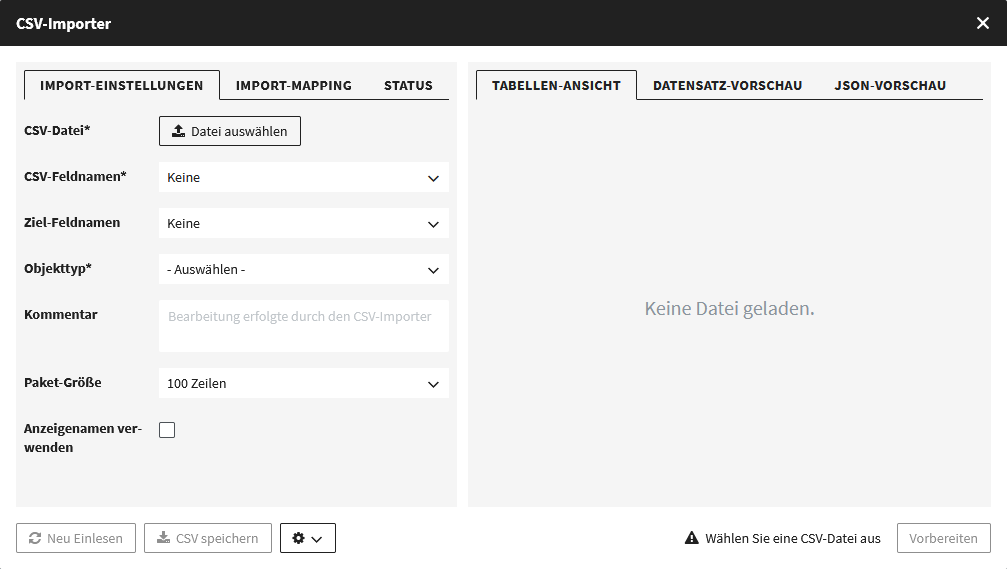
Im Importer gibt es zur Linken zwei Reiter mit Einstellungen, “Import-Einstellungen” und “Import-Mapping”, und einen Reiter “Status”.
Zur Rechten gibt es die Reiter “Tabellen-Ansicht”, “Datensatz-Vorschau” und “JSON-Vorschau”, die zur Übersicht dienen. “Tabellen-Ansicht” zeigt dir deine CSV-Datei an, die “Datensatz-Vorschau” zeigt dir an, wie der Ziel-Datensatz in CODA mit den gewählten Import-Einstellungen aussehen würde, und die “JSON-Vorschau” zeigt beides an.
Import-Mapping
Jedes Feld in deiner CSV-Datei bzw. deiner ursprünglichen Tabelle soll einem Feld in einem CODA-Datensatz zugeordnet werden. Diese Zuordnung nennt man auch Mapping.
Dabei entspricht jede Spalte in deiner CSV-Datei bzw. deiner ursprünglichen Tabelle einem Typ von Feld im Datenmodell von CODA. So stehen in einer Spalte zum Beispiel die Namen von allen Datensätzen, die du importieren willst. Der Spaltenname entspricht in den Import-Einstellungen dem “CSV-Feldnamen” und die Feldnamen im Datenmodell von CODA sind die “Ziel-Feldnamen”.
Der Workflow
- Überprüfe deine Daten / deine CSV-Datei:
- Entsprechen sie den Anforderungen an Daten und Formate?
- Sind sie insbesondere in UTF-8 oder UTF-16 kodiert?
- Beim Import von Listeneinträgen: Entsprechen die Einträge den Anforderungen an die Datenqualität?
- Wähle in der CODA-Nutzeroberfläche bei den Werkzeugen “CSV-Importer” aus.
- Import-Einstellungen: Hier wählst du deine CSV-Datei aus und gibst an, welche Art von Daten du wie importieren möchtest. Handelt es sich z.B. um Sammlungsobjekte oder um Materialien, die du in die Material-Liste importieren möchtest?
- Import-Mapping: Hier ordnest du jedem zu importierenden Feld in deiner CSV-Datei ein Feld in einem CODA-Datensatz zu. Je nach Größe deiner Tabelle kann dieser Schritt etwas mühselig sein, da z.B. verschachtelte Mehrfachfelder nicht immer automatisch zugeordnet werden.
- Wenn deine Einstellungen gesetzt sind, klicke rechts unten auf “Vorbereiten”
- Wenn im “Status”-Reiter keine Fehler auftauchen und in der Datensatz-Vorschau (rechts im Fenster) alles gut aussieht, dann kannst du die Daten einfügen bzw. aktualisieren, indem du rechts unten auf den entsprechenden Button klickst.
Soweit der Ablauf im Groben. Wichtig sind natürlich die Import-Einstellungen, die nun im Detail erläutert werden.
Import-Einstellungen
Im Reiter Import-Einstellungen findest du allgemeine Import-Einstellungen. Welche Datei willst du importieren, zu welchem Objekttyp in CODA sollen deine Daten werden, etc. Die Optionen sind im Folgenden aufgelistet. Viele dieser Optionen werden aber erst sichtbar, wenn man eine CSV-Datei eingelesen und eine Maske ausgewählt hat.
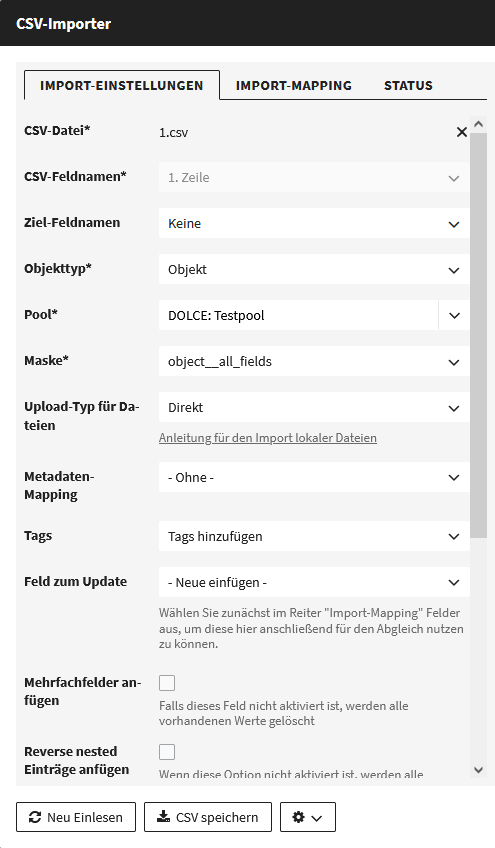

Optionen mit Sternchen (*) sind verpflichtend.
| Option | Erläuterung |
|---|---|
| CSV-Datei* | Wähle im File-Explorer deine CSV-Datei aus. |
| CSV-Feldnamen* | Wähle aus, in welcher Zeile deiner CSV-Datei die Feldnamen bzw. die Spaltentitel stehen. In aller Regel ist das die erste Zeile. |
| Ziel-Feldnamen | Hier soll man für automatisches Mapping Feldnamen angeben können, die Notation/Syntax für diese Option ist allerdings nicht offiziell dokumentiert. Ignoriere diese Option daher lieber. |
| Objekttyp* | Wähle aus, ob du Objekte, Digitalisate oder Einträge für eine der Listen in CODA importieren willst. |
| Pool* | Falls du als Objekttyp "Objekt", "Digitalisat" oder "Konvolut" (einen Hauptobjekttyp) ausgewählt hast, musst du hier noch wählen, welchem Pool du deine Objekte zuordnen willst. |
| Maske* |
Falls der Objekttyp "Objekt" ist, stehen je nach Berechtigungen mehrere Masken zur Verfügung. Wähle im Zweifelsfall "object__all_fields" aus.
Falls der Objekttyp nicht "Objekt" ist, sondern "Digitalisat", "Konvolut" oder eine Liste, dann gibt es hier i.d.R. eine spezifische Maske und je nach Berechtigung auch die Option "Alle Felder" zur Auswahl. Wähle im Zweifelsfall die spezifische Maske (z.B. für die Liste "Epoche": "era__all_fields"). |
| Upload-Typ für Dateien | Diese Option bestimmt, wie Dateien hochgeladen werden, die zu deinem Objekt gehören. Wähle hier im Zweifelsfall "Direkt". Die Option "URL (remote put)" ist für den Fall, dass die Dateien schon irgendwo per URL verfügbar sind, z.B. über einen lokalen Server. Diese Option ist zwar schneller, erfordert aber in der CSV-Datei auch eine entsprechende Spalte mit URLs. "Dateien ignorieren" ist eher für Testzwecke gedacht. |
| Tags | Für den Fall, dass du Datensätze aktualisierst, kannst du hier wählen, ob Tags, die in der CSV-Datei enthalten sind, zu den vorhandenen Tags hinzukommen oder vorhandene Tags ersetzen. |
| Feld zum Update |
Falls du bereits vorhandene Objekte oder Listeneinträge in CODA aktualisieren möchtest, dann muss erkannt werden, welche Zeile in deiner CSV-Datei einem Objekt in CODA zugeordnet werden soll. Standardmäßig wird hierfür der Name eines Datensatzes mit den Namen von CODA-Objekten abgeglichen. Falls ein Objekt mit Namen "Dein_Datensatz" schon in CODA vorhanden ist, würde dieses aktualisiert werden. Mit "Feld zum Update" kannst du auswählen, welches Feld statt des Namens zum Abgleich genutzt wird.
"- Neue einfügen -": Alle CSV-Zeilen werden zu neuen CODA-Einträgen Alle anderen Optionen: Wähle ein Feld, wenn damit vorhandene Einträge erkannt und aktualisiert werden sollen. (Alle anderen Optionen tauchen hier nur auf, wenn sie vorher im Reiter Import-Mapping zugeordnet worden sind.) |
| Mehrfachfelder anfügen | Diese Option ist nur bei Aktualisierung von Datensätzen relevant. Standardmäßig werden alle Informationen in Mehrfachfeldern durch die Inhalte in der CSV-Datei ersetzt, wenn du einen Datensatz aktualisierst - vorausgesetzt, dass die entsprechenden Spalten der CSV-Datei im Import-Mapping auch diesen Mehrfachfeldern zugeordnet sind. Ist jedoch "Mehrfachfelder anfügen" aktiviert, werden die Inhalte in der CSV-Datei stattdessen den Mehrfachfeldern hinzugefügt, vorausgesetzt sie enthalten Informationen, die bisher nicht im CODA-Datensatz vorhanden sind. Beachte, dass Stand 2024-03-14 die Vorschau nicht zuverlässig ist, wenn diese Option aktiviert ist. In der Vorschau werden nur die Mehrfachfelder angezeigt, die aus der CSV-Datei importiert werden, aber die bereits in CODA vorhandenen Informationen werden dadurch ergänzt, nicht überschrieben. |
| Reverse nested Einträge anfügen | Über sogenannte "reverse nested fields" kann man beim Erstellen eines Objekts auch gleich Bilder und Dateien hochladen, die dann als Digitalisat in CODA angelegt werden. Wenn du dieses Objekt erneut importierst und aktualisierst, würden die alten Bilder von den neuen Bildern überschrieben werden. Benutze diese Option, damit neue Bilder hinzugefügt werden statt überschrieben. (Diese Option erscheint, wenn du als Objekttyp "Objekt" wählst.) |
| Verlinkte Einträge anlegen | Wenn du ein Objekt importierst, das in einem Feld auf einen Listeneintrag verweist, dann wäre es natürlich unpraktisch, wenn dieser Listeneintrag noch nicht in CODA existiert. Wenn diese Option gewählt ist, werden solche nicht vorhandenen Einträge automatisch neu angelegt. |
| Pool für verlinkte Einträge* | Die Einträge, auf die vom Objekt verlinkt wird, gehören auch einem Pool an. Wähle hier standardmäßig denselben Pool wie weiter oben für dein Objekt. (Diese Option erscheint, wenn du als Objekttyp "Objekt" wählst.) |
| Kommentar | Hier kannst du einen Kommentar schreiben, der in der Änderungshistorie des Datensatzes auftaucht. |
| Paket-Größe | Lege fest, wie viele Datensätze der Importer in einem Rutsch importieren soll. Falls beim Import ein Fehler auftaucht, wird der Import des aktuellen Pakets abgebrochen. Falls Timeouts zum CODA-Server vorkommen, kann eine kleinere Paket-Größe helfen. |
| Anzeigenamen verwenden | Mit dieser Option stehen im Reiter "Import-Mapping" die Feldnamen zur Auswahl, wie sie auch in der Nutzeroberfläche von CODA angezeigt werden. Ansonsten werden standardmäßig die internen Feldnamen angezeigt. (Vgl. auch den Feldkatalog.) |
Import-Mapping
Damit im Reiter Import-Mapping überhaupt irgendwelche Felder angezeigt werden, musst du bei den Import-Einstellungen zuerst eine Maske auswählen. Deren Felder werden dann angezeigt.
Und zwar werden links alle Spaltennamen deiner CSV-Datei angezeigt. In den ausklappbaren Menüs rechts daneben werden dir alle Felder des Datenmodells angeboten, die auch in der gewählten Maske enthalten sind.
So kannst du dann für jede Spalte deiner Tabelle auswählen, mit welchem Feld im Datenmodell du ihre Inhalte verknüpfen willst. Dabei sind die Ansichten auf der rechten Seite des Fensters nochmal nützlich, um den Überblick zu behalten. Neben der “Datensatz-Vorschau” und “JSON-Vorschau” ist vor allem die “Tabellen-Ansicht” praktisch.
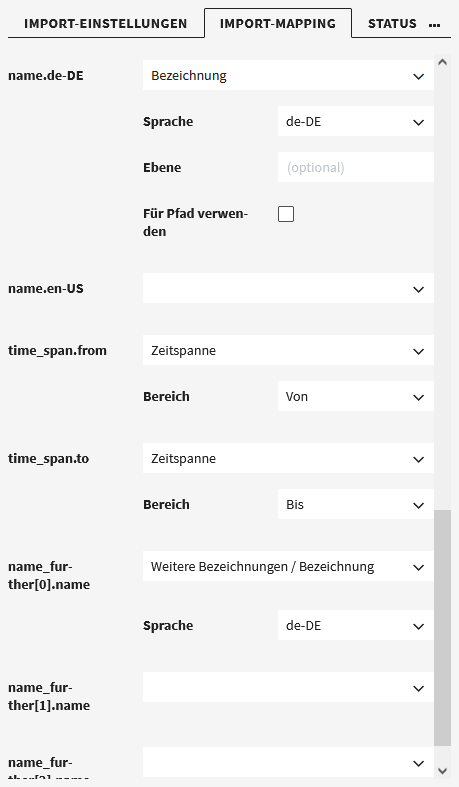
Hier ein Beispiel, wo die Import-Einstellung “Anzeigenamen verwenden” aktiviert ist. Der Spalte “name.de-DE” in der CSV-Datei wurde hier das Feld “Bezeichnung” im Datenmodell zugeordnet. Da dieses Feld sowohl eine deutsche als auch englische Variante hat, kann man deshalb auch noch die Sprache “de-DE” auswählen.
Vorsicht beim Aktualisieren mit leeren Feldern
Wenn du vorhandene CODA-Datensätze aktualisierst und in deiner CSV-Datei gibt es leere Felder, dann musst du aufpassen. Die entsprechenden Felder im Datensatz werden dann nämlich standardmäßig von den leeren Feldern in der CSV überschrieben. Welche Felder das tatsächlich sind, hängt davon ab, was du beim Import-Mapping ausgewählt hast. Wenn du beim Import-Mapping keine Zuordnung vorgenommen hast, wird auch nichts verändert.Upload-Template
Daten, die für den CSV-Import vorgesehen sind, können auf ähnliche Weise wie in diesem Template formatiert werden: Download des CSV-Upload-Templates (.xslx, 673 KB)
Es handelt sich hierbei um ein Template für Objektdatensätze. Bei Listeneinträgen sind die Felder andere (siehe auch Listeneinträge anlegen), aber das Prinzip ist im Grunde das gleiche. Auf Anfrage können wir auch beispielhaft ein Template für die Einträge einer Liste bereitstellen. Da je nach Liste die Felder variieren, müsste das Listen-Template dann auch entsprechend für andere Listen angepasst werden.
In der folgenden Auflistung sind die Spaltentypen im Upload-Template mit ihrer Beschreibung angegeben. Dabei entspricht bspw. der Spaltentyp “Objekttitel (Pflichtfeld)” einer Spalte im Upload-Template bzw. einem Feld im Datenmodell von CODA. Eine Zeile im Upload-Template entspricht dann einem konkreten Datensatz eines Sammlungsobjektes, siehe dafür das Template. Und die Information in einem Feld des Templates entspricht der Information, die in CODA in einem bestimmten Datensatz in einem bestimmten Feld landet.
Bedingte Pflichtfelder beziehen sich hier auf die Mehrfachgruppe “Ereignis” (siehe dazu Datensätze anlegen - Objektbiographie). Jedes Objekt soll mindestens ein Ereignis mit Ereignistyp haben, der Ereignistyp ist also ein Pflichtfeld. Und innerhalb der Mehrfachgruppe Ereignis soll dann noch zumindest eines der folgenden Unterfelder ausgefüllt werden: Ort, Datierung, Epoche, Person, Gruppe, Institution. Dies sind also bedingte Pflichtfelder, denn es müssen nicht alle von ihnen ausgefüllt werden, nur mindestens eins.
| Spaltentyp | Beschreibung/Inhalte |
|---|---|
| Objekttitel (Pflichtfeld) | Eine möglichst sprechende Bezeichnung, die später als Titel des Datensatzes angezeigt wird. Falls bisher keine Bezeichnung existiert, kann bspw. mit diesem Format eine erstellt werden: "Objektart Sammlungskürzel-Inventarnummer". Die Inventarnummer wird von der jeweiligen Sammlung festgelegt, das festgelegte Sammlungskürzel kann in der Dokumentation eingesehen werden. |
| Inventarnummer (Pflichtfeld) | Sammlungskürzel der Nummer voranstellen. Die Inventarnummer sollte wenn möglich am physischen Objekt angebracht sein. |
| Sammlung (Pflichtfeld) | Die Sammlung (an der Goethe-Universität), die das Objekt verwahrt oder die dem Datensatz zugeordnet werden kann. Die hierarchisch angelegte Liste, auf die das Feld verweist, enthält auch andere Institutionen. Bitte innerhalb der Goethe-Universität die entsprechende Sammlung auswählen bzw. anlegen. Sollte die Sammlung aus mehreren Teilsammlungen bestehen, können auch Untersammlungen angelegt werden. |
| Objektart (Pflichtfeld) | Mit diesem Pflichtfeld soll so präzise wie möglich der Typ des Objekts bezeichnet werden. Die zugehörigen Listeneinträge sollten unbedingt mit Normdaten angereichert werden. Mehrere Einträge können mit Zeilenumbruch (Alt + Enter) untereinander geschrieben werden. Einträge müssen in CODA vorhanden sein (Liste "Objektarten", ggf. vorab anlegen) |
| Lizenz an Metadaten (Pflichtfeld) | Beschreibt, unter welcher Lizenz die Daten, aus denen dieser Datensatz besteht, genutzt oder weiterverbreitet werden dürfen. Das betrifft nicht die verknüpften Digitalisate, die haben jeweils eigene Lizenzen! Begriff muss in CODA vorhanden sein (Liste "Lizenztypen") |
| Ereignis - Ereignistyp (Pflichtfeld) | Jeder Datensatz muss nach minimaldatensatz.de mindestens ein Ereignis enthalten, zu dem zwingend ein Ereignistyp (bspw. Herstellung, Kauf oder Raub) sowie entweder eine Datierung, ein Ort, eine Person oder Institution angegeben werden muss. Die möglichen Ereignistypen sind durch die LIDO-Terminologie definiert. Begriff muss in CODA vorhanden sein (Liste "Ereignistyp") |
| Ereignis - Ort (bedingtes Pflichtfeld) | Begriff muss in CODA vorliegen (Liste "Orte", ggf. vor Upload anlegen) |
| Ereignis - Datum (von) (bedingtes Pflichtfeld) | Immer sowohl von als auch bis ausfüllen, ggf. das gleiche Datum hineinschreiben |
| Ereignis - Datum (bis) (bedingtes Pflichtfeld) | Immer sowohl von als auch bis ausfüllen, ggf. das gleiche Datum hineinschreiben |
| Ereignis - Epoche (bedingtes Pflichtfeld) | Begriff muss in CODA vorhanden sein (Liste "Epochen", ggf. vor Upload anlegen) |
| Ereignis - Person (bedingtes Pflichtfeld) | Eine Person, die am beschriebenen Ereignis beteiligt war. Der Name muss in CODA vorhanden (Liste "Personen", ggf. vor Upload anlegen) |
| Ereignis - Gruppe (bedingtes Pflichtfeld) | Gruppe, die am beschriebenen Ereignis beteiligt war. Begriff muss in CODA vorhanden sein (Liste "Gruppen", ggf. selbst anlegen) |
| Ereignis - Institution (bedingtes Pflichtfeld) | Institution, die am beschriebenen Ereignis beteiligt war. Begriff muss in CODA vorhanden sein (Liste "Institutionen", ggf. selbst anlegen) |
| Ereignis - Kurzbeschreibung | Freitext-Kurzbeschreibung zum Ereignis |
| Digitalisate | Falls die Digitalisate bereits in CODA hochgeladen sind, hier den Dateinamen verwenden. Ansonsten müssen diese über einen lokalen Server bereitgestellt werden: https://docs.fylr.io/for-administrators/tools/csv-importer/examples/files Mehrere Digitalisate können mit Zeilenumbruch (Alt + Enter) untereinander geschrieben werden |
| Lizenz an Digitalisaten | funktioniert noch nicht |
| Beschreibung | Mehrere Beschreibungen können mit Zeilenumbruch (Alt + Enter) untereinander geschrieben werden |
| Botanischer Name | Begriff muss in CODA vorhanden sein (ggf. vorab selbst anlegen) |
| Material | Angabe der Materialien, aus denen ein Objekt oder Werk beschaffen ist. Begriff muss in CODA vorhanden sein (ggf. vorab selbst anlegen). Mehrere Materialien können mit Zeilenumbruch (Alt + Enter) untereinander geschrieben werden |
| Technik | Angabe der Technik, die bei der Herstellung, Präparation oder Aufbewahrung/Lagerung des Objekts oder Werks verwendet wurde. Begriff muss in CODA vorhanden sein (ggf. vorab selbst anlegen). Mehrere Techniken können mit Zeilenumbruch (Alt + Enter) untereinander geschrieben werden |
| Motiv | Bezeichnung eines Motivs, das auf dem Objekt/Werk abgebildet oder eines Themas, das vom Objekt oder Werk behandelt wird. Begriff muss in CODA vorhanden sein (ggf. vorab selbst anlegen). Mehrere Motive können mit Zeilenumbruch (Alt + Enter) untereinander geschrieben werden |
| Schlagwörter | Begriff muss in CODA vorhanden sein (ggf. vorab selbst anlegen) Mehrere Schlagworte können mit Zeilenumbruch (Alt + Enter) untereinander geschrieben werden |
| Maße: Dimension | Nur Begriffe aus Liste "Maße: Dimensionen" in CODA verwenden |
| Maße: Wert | Mehrere Maße können mit Zeilenumbruch untereinander geschrieben werden, jedoch muss in gleicher Zeile immer Dimension und Einheit vorhanden sein. Punkt als Dezimaltrennzeichen |
| Maße: Einheit | Nur Begriffe aus Liste "Maße: Einheiten" in CODA verwenden |
| Standardmaß | Nicht verwenden, wenn bereits andere reguläre Maße eingetragen wurden! Nur Begriffe aus Liste "Maße: Standardformate" in CODA verwenden |
| Zustand | Freitext-Feld |
| Anmerkung öffentlich | Freitext-Feld |
| Anmerkung intern | Diese Anmerkungen sind nur für Personen sichtbar, die Schreibrechte im Pool haben |
| Aufbewahrungsort | Freitext-Feld |
Bei dem Template handelt es sich allerdings nicht um das vollständige Datenmodell (siehe hierzu den Feldkatalog). Falls du noch Informationen für weitere CODA-Felder hinzufügen möchtest, brauchst du nur eine neue Spalte dafür anzulegen.
Häufig sind die Daten auch schon in einer tabellarischen Form vorhanden. In dem Fall musst du prüfen, ob die Tabelle den Anforderungen an Daten und Formate genügen, damit es beim Import nicht zu Komplikationen kommt.
Wie im Import-Workflow nachzulesen ist, kann man im CSV-Importer die Zeilen der Tabelle händisch einem beliebigen CODA-Feld zuordnen. Wenn man die Tabellenzeilen aber im Vorhinein schon mit den passenden Feldnamen benennt, dann kann der CSV-Importer das teilweise automatisch zuordnen. Das wurde im Template auf den Sheets “import-file_de” und “import-file_en” gemacht (siehe dort).
Das sieht in der Tabelle mit den verschachtelten Feldnamen vielleicht nicht so schön aus, aber man kann sich beim Import dadurch etwas Geklicke ersparen. All diese Feldnamen sind auch im Feldkatalog verzeichnet.